Mixture of Formats (MOF) & Mega Prompt Engineering
Dive deep into the art and science of advanced prompt engineering. This comprehensive guide explores cutting-edge techniques like Mixture of Formats (MOF), Mega-Prompts, and Ethical Prompting to help you unlock peak AI performance, ensure fairness, and mitigate bias for safer, more reliable results.


The quality of our interaction through prompts with large language models (LLMs) dictates the quality of their output. We've moved beyond simple questions and commands, entering an era where the construction of the prompt is as much an art as it is a science. This evolving discipline, known as prompt engineering, is no longer a niche skill but a fundamental competency for anyone looking to leverage the full potential of AI. It is the key that unlocks nuanced understanding, creative generation, and complex problem-solving from these powerful tools. As businesses and individuals integrate AI deeper into their workflows, mastering this dialogue is paramount.
This article serves as a comprehensive exploration into the sophisticated frontier of prompt engineering. We will journey beyond the basics to uncover the advanced techniques that are setting new standards for AI interaction and performance. The discussion will navigate through the intricate details of emerging strategies, including the robustness-enhancing Mixture of Formats (MOF), the context-rich power of Mega-Prompts, and the crucial practice of Ethical Prompting. These methodologies represent the pinnacle of current thinking, designed to systematically craft interactions that maximize AI efficacy while championing fairness and safety. Prepare to transform your understanding of AI conversations and learn how to architect prompts that lead to truly intelligent outcomes.
Why Advanced Prompting Matters
The initial wave of excitement surrounding large language models was fueled by their seemingly magical ability to understand and generate human-like text from simple instructions. This accessibility was crucial for widespread adoption, allowing millions to experiment with the technology. However, as users transitioned from novelty to practical application, they quickly encountered the limitations of basic prompting, a phenomenon often referred to as "prompt brittleness." Small, semantically irrelevant changes to a prompt's wording or format could lead to drastically different, and often degraded, performance, revealing the sensitive and sometimes unpredictable nature of these complex systems.
This challenge gave rise to the necessity of a more deliberate and structured approach to crafting AI instructions. Advanced prompt engineering is the answer to this need, providing a framework for creating robust, detailed, and context-aware prompts that guide the AI more precisely toward the desired output. It acknowledges that an LLM is not a mind-reader but a probabilistic text generator that relies heavily on the cues provided in the prompt. By refining these cues, we can significantly reduce ambiguity, minimize the chance of the model "hallucinating" or generating incorrect information, and unlock more sophisticated reasoning capabilities that are essential for complex tasks in fields like software development, legal analysis, and scientific research.
Furthermore, the impact of advanced prompting extends far beyond mere accuracy; it is fundamentally about control and reliability. In professional and commercial settings, the ability to consistently generate high-quality, predictable outputs is non-negotiable. Advanced techniques allow developers and users to build more resilient AI-powered applications, from customer service bots that handle nuanced queries with grace to content creation tools that adhere strictly to brand voice and style guidelines. This level of control is what elevates AI from an interesting gadget to an indispensable industrial tool, driving efficiency and innovation across sectors and cementing the role of the prompt engineer as a key architect of our digital future.
Mastering these techniques is therefore not just about getting better answers from a chatbot; it is about shaping the behavior of AI systems to be more aligned with human goals. It involves a deeper understanding of how these models "think" and a strategic approach to providing the context, examples, and constraints they need to perform at their peak. As we delve into specific methodologies like MOF, Mega-Prompts, and Ethical Prompting, we will see how each contributes to this overarching goal, offering a powerful toolkit for anyone serious about harnessing the transformative power of artificial intelligence. This journey into advanced prompting is a critical step towards a future where human-AI collaboration is more seamless, productive, and responsible.
Mixture of Formats (MOF)
One of the most significant challenges in practical prompt engineering is the inherent "brittleness" of LLMs, where minor, non-semantic variations in prompt styling can cause substantial performance fluctuations. An AI might perform exceptionally well when a question is phrased one way but fail when presented in a slightly different format, even if the core instruction remains identical. This sensitivity can undermine the reliability of AI applications. To combat this, researchers have developed an innovative technique known as Mixture of Formats (MOF), a strategy inspired by style diversification methods used in the field of computer vision to create more resilient models.
The core principle of MOF is simple yet remarkably effective: it involves diversifying the formatting styles of the few-shot examples provided within a single prompt. Instead of presenting all in-context learning examples in a uniform structure, MOF presents each one in a distinct style. For instance, one example might be a straightforward question-and-answer pair, another might be framed as a JSON object, a third could be structured as a formal instruction, and a fourth might use an XML-like syntax. This variety effectively teaches the model to focus on the underlying task and the semantic content of the examples, rather than overfitting to a specific presentation style.
The efficacy of Large Language Models (LLMs) is inextricably linked to the quality and design of the prompts they receive. Prompt engineering, the discipline of crafting these inputs, has emerged as a cornerstone for unlocking the vast potential of these sophisticated AI systems. It serves as the critical interface between human intention and the complex computational processes of machine execution. Well-architected prompts are paramount for guiding LLMs to produce responses that are not only accurate but also contextually relevant and appropriately structured. Conversely, inadequately formulated prompts can lead to outputs that are suboptimal, tangential to the query, or, in some instances, actively misleading. This underscores the pivotal role of meticulous prompt design in achieving desired outcomes from LLM interactions.
The field has witnessed a significant maturation, transitioning from rudimentary queries to highly advanced prompting methodologies. While straightforward prompts may suffice for elementary interactions, the increasing complexity of tasks assigned to LLMs necessitates more sophisticated and nuanced approaches. The evolution of prompt engineering has moved beyond simple heuristics to encompass a diverse array of strategies, including refined formatting techniques, structured reasoning scaffolds, explicit role assignments for the LLM, and even considerations for adversarial robustness. This progression is propelled by two interconnected factors: the expanding scope of applications for which LLMs are deployed and the continuous advancements in LLM architecture, such as the development of models with significantly larger input context windows (e.g., GPT-4o, Claude 3 Opus, Gemini 1.5 Pro). These larger context windows, in particular, have opened new avenues for incorporating more extensive information and examples directly within the prompt.
Within this dynamic landscape, specialized techniques such as Mixture of Formats (MOF) and Mega-Prompts have emerged to address distinct challenges inherent in LLM interaction. MOF, for instance, targets the issue of "prompt brittleness," where LLMs exhibit undue sensitivity to minor, non-semantic stylistic changes in prompts. Mega-Prompts, on the other hand, cater to the need for comprehensive and highly detailed instructions, particularly when guiding LLMs through intricate tasks or when aiming for outputs that adhere to very specific requirements. These advanced techniques signify a deliberate movement towards engineering LLM interactions that are more robust, reliable, and precisely controllable.
The practice of prompt engineering, especially at its advanced stages, can be understood as a method for modulating an LLM's exploration of its own vast latent space of knowledge and capabilities. Basic prompts might only activate broad, general regions within this space. In contrast, advanced techniques, such as Mega-Prompts with their rich contextual details and explicit constraints, or MOF by desensitizing the model to superficial stylistic variations, function as more precise instruments. They guide the LLM's generative process towards specific, desired regions of its learned abilities. This directed navigation serves to diminish ambiguity in the model's interpretation and consequently enhance the reliability of its outputs.
This increasing sophistication in prompt engineering also redefines the human role in LLM interaction. The human operator transitions from being a mere user posing questions to an "AI interaction designer." This evolved role involves the meticulous construction of intricate interaction frameworks—the prompts themselves—that proactively anticipate potential failure modes, steer the model's reasoning pathways, and meticulously structure its outputs. Such a shift necessitates a confluence of skills, blending linguistic proficiency, logical acumen, domain-specific expertise, and a nuanced understanding of LLM behavior. The growing demand for specialized "prompt engineers" in various industries corroborates this transformation into a distinct and valuable skill set.
Furthermore, the adoption of advanced prompting strategies carries significant economic implications. The capacity to craft prompts that elicit precise, dependable, and efficient responses from LLMs can yield direct financial benefits. It can obviate the need for extensive and costly model fine-tuning, curtail errors and hallucinations that would otherwise necessitate expensive human review or lead to suboptimal business outcomes , and optimize the utilization of computational resources, thereby reducing operational costs. Consequently, mastery of advanced prompt engineering is becoming a crucial determinant in maximizing the return on investment for LLM deployments across diverse applications.
Mixture of Formats (MOF) Enhancing LLM Robustness to Stylistic Variations
A significant hurdle in leveraging LLMs effectively is their inherent sensitivity to superficial changes in prompt presentation, a phenomenon known as "prompt brittleness". LLMs can exhibit substantial performance fluctuations in response to minor, non-semantic alterations in the format of few-shot examples within a prompt, such as the addition of extra spaces, changes in punctuation like colons, or variations in the ordering of examples. This brittleness undermines the reliability of LLMs, particularly in high-stakes applications such as healthcare, where consistent and predictable performance is paramount. Much of the early research in prompt engineering focused on identifying an "optimal" prompt for a given task, often overlooking this fundamental issue of sensitivity to minor stylistic deviations.
Core Principles and Methodology of MOF
Mixture of Formats (MOF) emerges as a direct response to this challenge. It is a straightforward yet potent technique designed to bolster LLM robustness by systematically diversifying the formatting styles used for few-shot examples within a single prompt. The core idea is that each input-output demonstration provided to the LLM is presented using a distinct stylistic convention.
The conceptual underpinning of MOF is drawn from established practices in computer vision, where models are trained on datasets featuring diverse styles (e.g., images of the same object under different lighting conditions, angles, or artistic renderings). This exposure helps computer vision models to disentangle core object features from superficial stylistic attributes, thereby preventing them from erroneously associating specific styles with the target variable and improving generalization. MOF translates this principle to the domain of language models.
The mechanism through which MOF operates is by intentionally varying the presentation of few-shot examples. This diversification aims to discourage the LLM from overfitting to any single presentational style. Instead, it encourages the model to focus on the underlying semantic content and the task logic embedded within the examples. To further reinforce this desensitization to style, some implementations of MOF also include an instruction for the LLM to rephrase or rewrite the question and answer pair of each provided example using yet another different format style. This active manipulation of format by the LLM itself may further solidify its ability to generalize across stylistic variations.
Empirical Validation: Key Findings on MOF's Impact
The efficacy of MOF has been investigated through empirical studies, comparing its performance against traditional few-shot prompting methods where all examples typically adhere to a uniform style. These studies have yielded several key findings, primarily based on experiments using a range of LLMs (including Falcon, Llama-2, and Llama-3 variants) and diverse datasets sourced from benchmarks like SuperNaturalInstructions, which cover tasks such as text categorization, stereotype detection, and textual entailment.
A primary outcome is the significant reduction in prompt brittleness. Brittleness is often quantified by the "spread," which measures the performance difference (e.g., in accuracy) between the best-performing and worst-performing prompt formats when subjected to minor stylistic changes. MOF has demonstrated the ability to considerably narrow this spread. For instance, in one documented task (task280), the application of MOF resulted in a 46% reduction in brittleness when using the Llama-2-13b model.
Beyond reducing the variance in performance, MOF has also shown a tendency to improve the absolute performance bounds. This means that MOF often raises both the minimum accuracy (the performance floor achieved with the least effective format variation) and, in many cases, the maximum accuracy (the performance ceiling achieved with the most effective format variation) compared to traditional prompting approaches.
Consequently, MOF prompts generally exhibit comparable or enhanced overall average accuracy when performance is averaged across multiple prompt format variations. This suggests that MOF not only makes LLM performance more consistent but can also elevate it.
It is important to note, however, that MOF's benefits are not universally absolute across every conceivable task, dataset, and model combination. Studies have reported instances where traditional prompting methods still yielded better performance on specific datasets with particular models. This underscores the continued importance of empirical testing and validation when implementing any prompting strategy, including MOF.
Practical Implementation Guidelines and Considerations for MOF
In practice, MOF is implemented within the framework of few-shot prompting. Instead of presenting all input-output demonstrations in a uniform manner, each example is deliberately styled differently. These "styles" can encompass a range of non-semantic alterations, including but not limited to:
Changes in delimiters (e.g., using "Input:... Output:..." for one example, and "Q:... A:..." for another).
Variations in phrasing (e.g., "Translate this sentence:" vs. "French translation:").
Different ordering of elements within an example, provided the core meaning is preserved.
Use of bullet points, numbered lists, or plain paragraph styles for different examples.
The key is that these variations should not alter the fundamental meaning or the task being demonstrated by the example.
Looking ahead, researchers anticipate integrating MOF with other advanced prompting techniques. For instance, its principles could be applied to the examples used in Chain-of-Thought (CoT) prompting or combined with methods like Automatic Prompt Engineer (APE) to automate the generation of stylistically diverse examples.
The application of MOF can be seen as a form of implicit regularization for LLMs during the in-context learning phase. In conventional machine learning, regularization techniques are employed to prevent models from overfitting to the training data, often by adding a penalty for complexity or by introducing noise or variability. MOF achieves a similar effect at inference time. By exposing the LLM to a variety of stylistic presentations within its prompt, it discourages the model from latching onto superficial, format-specific patterns in the few-shot examples. This, in turn, compels the LLM to focus on learning the more general, underlying task structure, thereby promoting better generalization from the provided examples.
The very effectiveness of MOF sheds light on a characteristic of current LLMs: they can exhibit a form of "stylistic bias." This means that the presentation format of information can unduly influence their processing and output, analogous to how framing effects can sway human judgment. MOF's success in mitigating this sensitivity suggests that, without explicit guidance or techniques like MOF, LLMs may not perfectly or consistently separate the form of information from its content. This has broader implications for how we conceptualize LLM "understanding" and their ability to process information abstractly.
Furthermore, the adoption of MOF could alleviate some of the burdens associated with hyper-specific prompt tuning. A considerable amount of effort in prompt engineering is often dedicated to discovering the "perfect" prompt format that elicits optimal performance from a specific model for a given task. If MOF renders models more robust to stylistic variations, it could diminish the necessity for such exhaustive and often painstaking searches for a single, uniquely optimal format. Engineers could then redirect their focus towards ensuring the high quality of the examples and the clarity of the instructions, with greater confidence that minor formatting choices are less likely to derail the model's performance. The development of metrics like FormatSpread , which quantifies this performance variability due to format changes, highlights the problem that MOF aims to solve by reducing this spread.
The inspiration MOF draws from computer vision—where techniques like style transfer and the use of diverse datasets help models learn core object features independent of stylistic presentation —is particularly pertinent. If LLMs can be trained or prompted to effectively disregard stylistic variations in textual inputs, it may represent a step towards them developing more abstract, format-independent representations of tasks and concepts. Such an advancement would be crucial for achieving a more human-like level of generalization, where the essence of a task or piece of information is understood irrespective of the precise manner in which it is phrased or presented.
Mega-Prompts
As we push the boundaries of what AI can achieve, the complexity of our requests naturally increases. Simple, single-sentence prompts are often insufficient for tasks that require deep domain knowledge, nuanced creativity, or multi-step reasoning. This is where the concept of "Mega-Prompts" comes into play, representing a paradigm shift towards providing LLMs with extensive, highly detailed, and contextually rich instructions. A Mega-Prompt is not just a question; it is a comprehensive brief, often spanning hundreds or even thousands of words, that leaves very little to the model's interpretation.
The fundamental idea behind a Mega-Prompt is to front-load the AI with all the necessary information it needs to execute a complex task flawlessly. This can include a wide array of components designed to guide the model’s behavior with surgical precision. For example, a Mega-Prompt might include an assigned persona (e.g., "Act as a senior marketing analyst with 15 years of experience in the tech sector"), a detailed step-by-step workflow to follow, specific constraints and negative constraints (what not to do), and a library of relevant examples or data. By creating such a detailed operational framework, we move from suggesting a task to directing a process, drastically increasing the quality and relevance of the output.
The power of this technique is particularly evident in professional domains. A legal team could use a Mega-Prompt to have an AI analyze a contract, providing it with the relevant legal statutes, definitions of key terms, and the specific questions to address, resulting in a far more rigorous analysis than a simple "review this document" command. Similarly, a software development team could use a Mega-Prompt containing coding standards, library documentation, and desired architectural patterns to generate high-quality, production-ready code. This level of detail mitigates the risk of generic or incorrect outputs and aligns the AI’s performance with expert-level standards.
However, crafting effective Mega-Prompts is a sophisticated skill that comes with its own set of challenges. One primary concern is the "lost in the middle" problem, where models tend to pay more attention to information at the beginning and end of a long context window, potentially ignoring critical details in the middle. To mitigate this, prompt engineers use techniques like hierarchical structuring, breaking the prompt into logical chunks with clear headings, and strategically repeating key instructions or context. Despite these complexities, the mastery of Mega-Prompts is becoming a hallmark of advanced AI usage, enabling users to tackle intricate, multi-faceted tasks and unlock a new dimension of controlled, high-fidelity AI generation.
As LLMs are tasked with increasingly complex and nuanced objectives, the need for more elaborate and explicit guidance has given rise to the concept of "Mega-Prompts." These represent a significant departure from the concise queries often associated with simpler LLM interactions.
Defining Mega-Prompts
Mega-Prompts are defined as enhanced, highly detailed instructions provided to an LLM to meticulously guide its responses and actions. A defining characteristic is their length and comprehensiveness; they can often span one to two pages of text, providing a rich tapestry of information intended to shape the LLM's output with precision.
This contrasts sharply with standard prompts, which are typically brief and may lack sufficient context to fully specify the desired outcome. While such brevity might be suitable for straightforward requests or open-ended creative generation, it often results in less control over the LLM's output and can lead to ambiguity. Mega-Prompts, by their nature, aim to minimize such ambiguity by furnishing extensive and precise directives. This approach is fundamentally different from the iterative, conversational clarification often employed in web-based chatbot interfaces, where users might refine their intent over several turns. Instead, a Mega-Prompt endeavors to provide all necessary guidance upfront.
Anatomy of an Effective Mega-Prompt
The construction of an effective Mega-Prompt involves the careful orchestration of several key components, designed to provide a holistic and unambiguous set of instructions to the LLM. A useful framework for conceptualizing these components is the "ASPECCTs" model (Action, Steps, Persona, Examples, Context, Constraints, Template), which synthesizes elements identified across various analyses of detailed prompting.
The following table details these core components, their descriptions, and their importance in crafting effective Mega-Prompts.
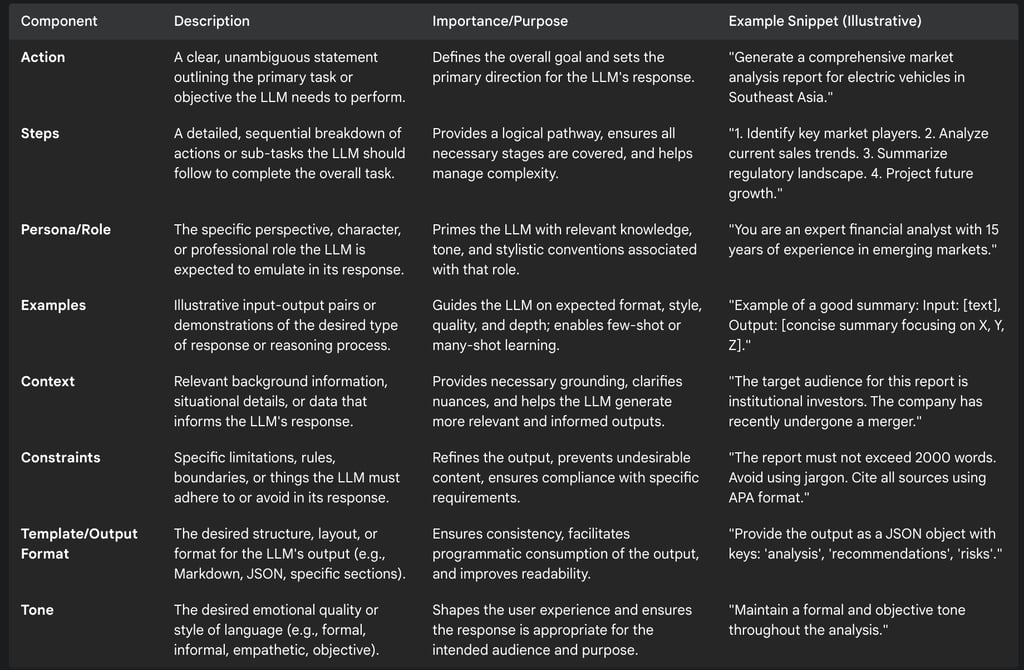
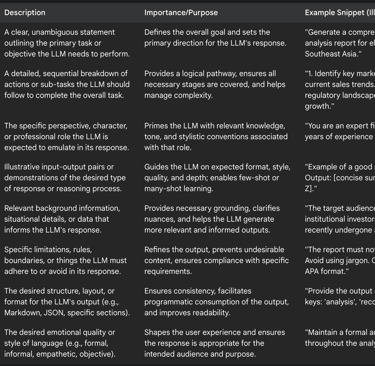
Beyond these components, effective structuring principles are vital. These include ensuring overall clarity and specificity in language, breaking down complex tasks into smaller, discrete, and manageable steps , using delimiters (such as --- or ###) to clearly separate different sections or instructions within the prompt , and maintaining a logical flow throughout the entire Mega-Prompt.
Strategies for Developing, Refining, and Iterating Mega-Prompts
The creation of a successful Mega-Prompt is rarely a single-step process; it typically involves an iterative cycle of development, testing, and refinement. Developers often begin with a simpler, core prompt and then progressively elaborate on it based on an analysis of the LLM's outputs and any identified shortcomings. This iterative fleshing-out process frequently culminates in the detailed structure characteristic of a Mega-Prompt.
Refinement involves critically evaluating the LLM's responses against the desired outcome and then adjusting the prompt accordingly. This might entail clarifying instructions, adding more specific context, providing better or more numerous examples, or imposing stricter constraints.
With the advent of LLMs possessing larger context windows, the strategy of "many-shot learning" has become increasingly viable within Mega-Prompts. This involves including dozens, or even hundreds, of examples directly within the prompt. Such a wealth of demonstrations can significantly enhance the LLM's ability to generalize and adhere to the desired patterns, often yielding superior results compared to traditional few-shot learning with a handful of examples.
Illustrative Applications and Use Cases for Mega-Prompts
The comprehensive nature of Mega-Prompts makes them particularly well-suited for a variety of complex applications:
Development of intricate LLM-powered workflows: Where the LLM needs to perform a sequence of operations or adhere to complex conditional logic.
Creative content generation requiring specific styles or detailed world-building: Such as drafting chapters for a novel with established characters and settings, or generating scripts for games with complex narratives.
Advanced text classification tasks: Where numerous examples can be provided within the prompt to teach the model fine-grained distinctions between categories.
Generation of structured data or code: Where the Mega-Prompt can specify the exact output schema, syntax, and logical requirements.
Multi-modal generation tasks: An innovative example involves using a detailed "scene-level prompt" (a form of Mega-Prompt) to guide AI image generation models to produce images from multiple consistent angles (front, back, side, etc.). These images, with their inherent structural logic, can then be fed into multi-image 3D generation tools to create complete 3D models with textures and solid topology, all initiated from a highly descriptive textual Mega-Prompt.
Tailored content creation for specific objectives: For example, generating a blog post that not only covers a technical topic but also maintains an engaging narrative style and aligns with a specific thematic focus, such as sustainability.
The detailed nature of Mega-Prompts allows for a form of "in-context fine-Tuning" or "task sculpting." While traditional fine-tuning involves modifying the underlying weights of a model through further training on specialized datasets, Mega-Prompts, particularly when augmented with many-shot examples and precise instructions regarding persona and style , can achieve a comparable level of task-specific adaptation entirely within the context window at inference time. This effectively "sculpts" the general-purpose LLM into a specialized performer for that specific interaction, offering considerable flexibility without the computational and logistical overhead associated with creating and maintaining distinct fine-tuned models.
This shift towards highly detailed upfront instruction also implies a reallocation of cognitive load. With shorter, less specific prompts, a significant portion of the "interpretive work"—discerning the user's precise intent and filling in contextual gaps—rests upon the LLM. This can lead to ambiguity and variability in responses. Mega-Prompts transfer a substantial part of this cognitive load to the human prompt designer. The designer must meticulously define the task parameters, provide rich context, articulate constraints, and curate illustrative examples. While this demands greater upfront human effort in prompt construction, it commensurately reduces the LLM's interpretive burden, thereby fostering more predictable, controlled, and aligned outputs.
Mega-Prompts can also serve as crucial enablers of complex agentic behavior in LLMs. For an LLM to function as an autonomous or semi-autonomous agent capable of performing multi-step tasks, engaging in reasoning, or utilizing external tools, it requires a comprehensive operational framework. Mega-Prompts are well-suited to provide this framework by explicitly defining the agent's role (persona), its overarching goals (action), the specific steps it should take, how it should process and utilize information (context), and what its operational boundaries are (constraints). Advanced prompting paradigms like ReAct (Reasoning + Acting) or Context-Aware Decomposition are, in essence, highly structured Mega-Prompts specifically engineered to elicit such sophisticated, agent-like behaviors from LLMs.
However, the pursuit of detail in Mega-Prompts is not without its nuances. While comprehensiveness is a hallmark , there exists an implicit trade-off. An excessive volume of poorly organized or contradictory detail can, paradoxically, confuse the LLM, leading it to ignore certain instructions or degrade its performance. The art of effective Mega-Prompting thus lies in identifying a "sweet spot"—providing information that is both exhaustive and impeccably structured, guiding the model effectively without overwhelming its processing capabilities or introducing internal conflicts. The quality and organization of the information embedded within a Mega-Prompt are therefore as critical as its sheer quantity. Furthermore, the inherent token limits of LLMs impose a practical ceiling on the verbosity and complexity that can be incorporated into any single prompt.
Comparative Insights: MOF and Mega-Prompts
While both Mixture of Formats (MOF) and Mega-Prompts represent advanced strategies in prompt engineering, they address different facets of LLM interaction and employ distinct methodologies. Understanding their unique goals, approaches, and trade-offs is crucial for their effective application.
Distinctive Goals and Approaches
The primary objective of Mixture of Formats (MOF) is to enhance the robustness of LLMs specifically against stylistic variations encountered in few-shot examples. It directly targets the problem of prompt brittleness, aiming to make LLM performance more consistent even when the presentation of examples changes in non-semantic ways. MOF's core approach involves diversifying the formatting style of each input-output demonstration within the prompt.
In contrast, Mega-Prompts are primarily concerned with providing comprehensive and meticulously detailed instructions to guide LLMs in the execution of complex tasks, ensuring outputs are accurate and conform to highly specific requirements. The approach of Mega-Prompting centers on increasing the depth, breadth, and structural clarity of the overall prompt, encompassing aspects like task definition, operational steps, persona, context, constraints, and desired output format.
Synergies and Potential for Combined Usage
Despite their different primary aims, MOF and Mega-Prompts are not mutually exclusive and can potentially be used synergistically. The principles of MOF can be effectively applied within the "Examples" component of a Mega-Prompt. If a Mega-Prompt incorporates few-shot (or even many-shot) learning by providing illustrative examples, presenting these examples using a mixture of formats could enhance the overall robustness of the Mega-Prompt. This would make the LLM less susceptible to being misled by minor stylistic inconsistencies in how those examples are written or how it interprets them, even while it processes the broader, complex instructions of the Mega-Prompt.
For instance, a Mega-Prompt might define a multi-faceted task requiring nuanced reasoning and a specific output structure. Within this Mega-Prompt, if few-shot examples are used to demonstrate a particular sub-skill or desired response pattern, applying MOF to these examples could help ensure that the LLM correctly learns the intended pattern without being unduly influenced by the specific stylistic choices made in those particular demonstrations. This allows the LLM to focus its resources on understanding the overarching complex instructions of the Mega-Prompt.
Contrasting Trade-offs
Each technique comes with its own set of benefits and challenges:
Mixture of Formats (MOF):
Benefit: Leads to increased robustness against stylistic variations in examples and can improve the LLM's generalization from these examples.
Cost/Challenge: Requires the effort of designing or sourcing multiple distinct yet semantically equivalent stylistic variations for each few-shot example. As empirical results show, MOF does not guarantee performance improvement across all tasks or models, necessitating testing.
Mega-Prompts:
Benefit: Affords a high degree of control over the LLM's output, enabling greater accuracy for complex tasks and the ability to specify detailed output structures and styles.
Cost/Challenge: Involves significant upfront investment in design, meticulous iteration, and refinement. They typically result in longer processing times due to their length and complexity, which translates to higher computational costs and latency. If poorly structured or overly prescriptive, they can inadvertently overwhelm the LLM or stifle its creative potential. Moreover, they are inherently constrained by the LLM's maximum token limit.
MOF and Mega-Prompts operate at different, albeit complementary, levels of the prompt engineering hierarchy. MOF is fundamentally concerned with improving the quality and reliability of in-context learning from specific exemplars. It achieves this by making the learning process less sensitive to superficial features of those exemplars. Mega-Prompts, conversely, are about defining the entire architecture of the task interaction. They specify the overarching goals, the sequence of operations, the persona the LLM should adopt, and the constraints it must observe. Thus, MOF can be seen as a technique that fine-tunes a sub-component (the interpretation of examples) which can, and often does, exist within the larger, more encompassing structure of a Mega-Prompt.
While the synergy between MOF and the "Examples" section of a Mega-Prompt is apparent, a potential for negative interaction could arise if MOF principles were applied indiscriminately to the structural elements of a highly organized Mega-Prompt. Many Mega-Prompts rely on extremely consistent formatting for their own internal clarity—for instance, using specific XML-like tags or Markdown headings to delineate distinct sections or instruction blocks. If MOF's stylistic diversification were aggressively applied to these crucial scaffolding elements (rather than just to the content of few-shot examples embedded within), it could inadvertently undermine the Mega-Prompt's overall structural coherence for the LLM, leading to confusion. This suggests a nuanced application: MOF is valuable for enhancing the robustness of example interpretation, while strict consistency is often preferable for maintaining the integrity of the Mega-Prompt's overarching framework.
This distinction also positions MOF more as a micro-technique, applicable at the granular level of individual few-shot examples, whereas Mega-Prompting is better characterized as a macro-framework or a broader architectural philosophy for prompt design. This difference has implications for their scalability and ease of deployment. One might develop a reusable library of MOF-stylized examples for common tasks, but crafting a Mega-Prompt is typically a more bespoke design process tailored to a specific, often large-scale, objective.
Best Practices for Implementing MOF and Mega-Prompts
Effective implementation of advanced prompting techniques like MOF and Mega-Prompts hinges on a set of best practices that enhance clarity, facilitate integration with other methods, streamline debugging, and manage resource constraints. Adherence to these practices can significantly improve the performance and reliability of LLM interactions.
The Role of Structured Formatting (e.g., Markdown, JSON, XML) in Enhancing Clarity and Efficacy
The use of structured formatting languages is paramount in crafting clear and effective prompts, particularly for complex instructions like those found in Mega-Prompts.
Markdown: This lightweight markup language is highly favored for its simplicity and readability, benefiting both human prompt designers and LLMs. Its ability to create clear sections, hierarchical levels using headings, and ordered or unordered lists makes it ideal for organizing instructions and breaking down complex tasks into discrete, digestible steps. The underlying principle, "Clear formatting → Clear thinking → Better Prompts," emphasizes that well-structured prompts are easier for both humans to write and edit, and for LLMs to parse and understand. LLMs appear to process Markdown efficiently due to its straightforward syntax. Furthermore, one can explicitly request the LLM to generate its output in Markdown format, ensuring the response is also well-structured.
JSON (JavaScript Object Notation) and XML (Extensible Markup Language): These formats are invaluable when the desired LLM output needs to be highly structured for programmatic consumption, such as feeding data into downstream applications or databases. For instance, a prompt might instruct the LLM to return its analysis as a JSON object with specific keys and value types. Advanced query languages like JSONiq even allow for the combination of XML and JSON, where JSON objects or arrays can contain XML nodes, offering flexibility in handling mixed data structures. Similarly, proposals like XMON (eXtensible Malleable Object Notation) suggest embedding JSON directly within XML start-tags, aiming to leverage the strengths of both formats.
Clear Separators and Delimiters: Employing distinct separators such as triple quotes ("""..."""), hyphens (---), colons, or bullet points is a simple yet effective way to delineate different parts of a prompt—such as instructions, context, examples, and the query itself. This visual and logical separation enhances the overall structure and clarity, reducing the likelihood of the LLM misinterpreting the prompt's components.
Integrating MOF and Mega-Prompts with Other Advanced Prompting Techniques
MOF and Mega-Prompts do not exist in isolation; their power can be amplified when strategically combined with other advanced prompting methodologies.
Chain-of-Thought (CoT) Prompting: Mega-Prompts provide an excellent framework for incorporating CoT reasoning. This can be achieved by explicitly instructing the LLM to "think step by step" before providing an answer , or by structuring the Mega-Prompt itself to guide the LLM through a logical sequence of reasoning stages. If CoT reasoning steps are demonstrated through few-shot examples within a Mega-Prompt, MOF principles could be applied to these examples to enhance robustness.
Role Prompting: Assigning a specific role or persona to the LLM (e.g., "You are an expert astrophysicist") is a core component often embedded within Mega-Prompts. This technique primes the LLM with the knowledge, vocabulary, and stylistic conventions associated with that role, leading to more contextually appropriate and informed responses.
Few-Shot and Many-Shot Learning: Mega-Prompts inherently leverage few-shot or many-shot learning by including illustrative examples to guide the LLM. MOF is specifically designed to enhance the effectiveness of these few-shot examples by diversifying their stylistic presentation.
Combining Multiple Prompt Types: The most effective prompts often result from a synthesis of various techniques. A Mega-Prompt can serve as the overarching structure that integrates role assignment, few-shot examples (potentially enhanced with MOF), chain-of-thought directives, and explicit output format constraints. For example, one might construct a Mega-Prompt that assigns a customer service agent role, provides several MOF-stylized examples of good and bad interactions, instructs the LLM to follow a specific problem-resolution workflow (CoT), and requires the final summary to be in a JSON format.
Techniques for Debugging, Troubleshooting, and Optimizing Complex Prompts
The development of complex prompts, especially Mega-Prompts, is an iterative process that often requires systematic debugging and optimization.
Iterative Refinement: This is a cornerstone of effective prompt engineering for both MOF (implied by its experimental validation) and Mega-Prompts (explicitly recommended ). The cycle involves designing the prompt, testing it with the LLM, analyzing the output for deviations from the desired outcome, and then refining the prompt based on this analysis.
Task Decomposition and Prompt Chaining: For highly complex tasks, attempting to achieve the desired output with a single, monolithic prompt can be challenging to develop and debug. A more manageable approach is to break the complex task into smaller, sequential sub-tasks, with each sub-task handled by a dedicated prompt. The output of one prompt in the chain can then serve as input for the next. This modularity simplifies debugging, as issues can be isolated to specific links in the chain.
Start Simple: When developing a complex prompt, it is often advisable to begin with a basic version containing only the core instructions and then incrementally add complexity, testing at each stage.
Test Each Part Individually: For multifaceted prompts like Mega-Prompts, verify the clarity and effectiveness of individual components, such as input data formatting, contextual information, and specific instruction blocks, before testing the entire prompt.
Consistency Checks: Ensure that similar inputs or minor variations of the same query yield consistent and predictable outputs from the LLM. Inconsistencies can signal ambiguity in the prompt.
Edge Case Testing: Actively challenge the prompt with unusual, unexpected, or complex inputs (edge cases) to identify potential weaknesses or failure modes.
Human Review: Despite automated testing possibilities, human evaluation of LLM outputs remains indispensable, particularly for critical applications where nuance, safety, or factual accuracy are paramount.
Troubleshooting Structured Output (e.g., JSON): If the LLM struggles to produce valid structured output, consult model-specific documentation for its capabilities in this area. Ensure the schema is provided in a valid format within the prompt. Using few-shot examples of the desired structured output can be highly effective. Consider employing a low "temperature" setting (e.g., 0.0) for the LLM to encourage more deterministic output. Pre-filling the assistant's response with the beginning of the expected structure (e.g., an opening curly brace for JSON) can also guide the model. For minor formatting errors in JSON output, utility libraries (e.g., json_repair) can sometimes correct them post-generation.
Navigating Token Limits and Optimizing for Efficiency
LLMs operate with finite "context windows," measured in tokens, which are the smallest units of text (often subwords or characters) the model processes. Every model has a maximum token limit (e.g., 4096, 8192, or even larger in newer models) that encompasses both the input prompt and the generated output. Mega-Prompts, due to their inherent length and detail, are particularly susceptible to these limits. Token optimization is crucial for several reasons :
Cost Efficiency: Most LLM APIs charge based on token usage. Minimizing tokens directly reduces operational costs.
Performance: Shorter prompts generally lead to faster response times from the LLM.
Resource Optimization: Efficient token usage optimizes computational resource allocation, important for scalability.
Improved LLM Focus: Concise prompts can help focus the LLM's attention on the most critical information, potentially leading to more relevant responses.
Techniques for token optimization include :
Crafting clear and concise instructions, avoiding unnecessary verbosity, repetition, or redundant details.
Using widely understood abbreviations and acronyms (e.g., "NASA" instead of "National Aeronautics and Space Administration").
Systematically removing superfluous words or phrases from the prompt without altering its core intent.
When possible, choosing LLM versions that are specifically optimized for token efficiency or employ more advanced subword tokenization schemes.
For Mega-Prompts, the extensive detail required must be carefully balanced against these token constraints. This necessitates a strategic approach to information inclusion, prioritizing the most impactful instructions and examples, and striving for conciseness wherever possible without sacrificing essential clarity.
The use of structured formatting, such as Markdown, JSON, or XML, does more than just aid human readability or facilitate programmatic parsing of outputs. These formats provide a predictable and organized structure that LLMs can learn to navigate and interpret more effectively. This structure acts as a form of "cognitive scaffolding," helping the LLM to segment information, discern hierarchies of instructions (e.g., main tasks versus sub-steps), and differentiate between various types of content within the prompt (such as an instruction, an example, or a piece of contextual information). This scaffolding likely reduces the cognitive load on the LLM when processing lengthy and complex prompts like Mega-Prompts, as suggested by observations that LLMs find well-structured formats like Markdown easier to understand.
The detailed processes described for debugging and refining prompts—such as task decomposition into chained sub-prompts , methodical testing of individual prompt components , rigorous analysis of edge cases , and continuous iterative refinement —bear a striking resemblance to established software debugging methodologies. This analogy suggests that complex prompts, particularly Mega-Prompts, can be conceptualized as "programs" written in a combination of natural language and structured formatting, designed to direct the LLM's computational "execution." The emerging need for practices like version control for prompts and validation of LLM outputs further reinforces this view of prompts as engineered artifacts.
Token optimization emerges as a fundamental constraint that significantly shapes the practical feasibility of deploying advanced prompting techniques. The inherent power of Mega-Prompts, for instance, derives from their rich detail and comprehensiveness , while MOF often requires the inclusion of multiple examples to showcase stylistic diversity. Both approaches can naturally lead to an increased token count. The hard limits on context length imposed by current LLM architectures , coupled with the per-token costs associated with API usage , create a persistent tension. This tension is between the desire for maximum prompt expressiveness and detail on one hand, and the imperative for operational efficiency and cost-effectiveness on the other. Consequently, ongoing research into more token-efficient LLM architectures, as well as techniques for more effectively compressing information within prompts without loss of meaning, will be crucial for the continued advancement and widespread practical application of sophisticated prompting strategies like Mega-Prompts.
Finally, the discussion surrounding the integration of various prompting techniques—such as MOF, CoT, role-prompting, and few/many-shot learning, often within the encompassing structure of a Mega-Prompt —points towards an increasingly compositional or modular approach to prompt design. Prompt engineers are moving beyond the application of isolated techniques and are instead learning to combine them strategically. This is akin to building with a set of versatile components, where each technique serves a specific purpose, and their thoughtful combination results in a more powerful, tailored, and effective overall prompt architecture. In many such compositions, Mega-Prompts serve as the foundational "chassis" or framework that holds and organizes these diverse prompting elements.
Addressing Limitations and Navigating Challenges
While MOF and Mega-Prompts offer significant advantages in specific contexts, they are not without their inherent limitations and potential challenges. Acknowledging these is crucial for realistic expectation setting and effective implementation.
Inherent Limitations of MOF
Not a Universal Solution: Although MOF has demonstrated efficacy in reducing prompt brittleness and often improving performance, it is not a panacea. Its superiority over traditional prompting methods is not guaranteed in every scenario, across all LLMs, or for every type of dataset. Empirical validation for specific use cases remains a necessary step.
Effort in Style Creation: The practical implementation of MOF requires the generation of genuinely diverse yet semantically consistent stylistic variations for the few-shot examples. This can involve a non-trivial amount of creative effort and careful design to ensure that the stylistic changes do not inadvertently alter the meaning or the task being demonstrated.
Focus on Style, Not Deeper Logic: MOF's primary strength lies in addressing sensitivity to stylistic presentation. It does not inherently rectify issues related to flawed logic within the few-shot examples themselves or fundamental misunderstandings of the overall task by the LLM. If the examples are poor quality to begin with, MOF is unlikely to make them effective.
Inherent Limitations of Mega-Prompts
Learning Curve and Design Effort: Crafting effective Mega-Prompts is a skill that demands a good understanding of the task domain, the capabilities and idiosyncrasies of the target LLM, and a willingness to engage in significant iterative design and refinement. This can represent a steep learning curve for novice prompt engineers.
Processing Time and Cost: Due to their considerable length and complexity, Mega-Prompts naturally require more tokens to be processed by the LLM. This translates to longer response latencies and higher computational costs, especially when using API-based LLM services that charge per token.
Potential for Over-Constraining and Reduced Creativity: While the goal of Mega-Prompts is often to achieve precise control, highly detailed and prescriptive prompts can sometimes stifle the LLM's inherent creativity or its ability to find novel or more efficient solutions that were not explicitly outlined by the prompt designer.
Risk of Confusion if Poorly Structured: If a very long and complex Mega-Prompt is not meticulously structured with clear delineation of sections, consistent formatting, and logical flow, it can risk confusing the LLM. This can lead to certain instructions being ignored, misinterpretations, or a general degradation in the quality of the output.
Token Limits: The maximum context window of an LLM imposes an unavoidable physical constraint on the length and thus the amount of detail that can be packed into a Mega-Prompt. Designers must work within these boundaries, making careful choices about what information is most critical to include.
Common Pitfalls and How to Avoid Them
Navigating the implementation of MOF and Mega-Prompts requires awareness of common pitfalls:
For MOF:
Pitfall: Introducing stylistic changes that inadvertently alter the semantic meaning of the examples.
Avoidance: Exercise meticulous care in designing stylistic variations, ensuring they are truly non-semantic and preserve the core task demonstration.
Pitfall: Expecting MOF to compensate for fundamentally poor-quality or irrelevant few-shot examples.
Avoidance: Prioritize the selection and crafting of high-quality, relevant, and clear examples first; MOF is an enhancement, not a remedy for bad examples.
For Mega-Prompts:
Pitfall: Creating information overload by providing excessive detail without clear structure, leading to LLM confusion.
Avoidance: Employ structured formatting (e.g., Markdown), use clear delimiters and section headings, and ensure a logical progression of instructions.
Pitfall: Including conflicting or contradictory instructions within the same Mega-Prompt.
Avoidance: Thoroughly review the entire prompt for internal consistency and unambiguous directives.
Pitfall: Neglecting the iterative nature of Mega-Prompt development, expecting perfection on the first attempt.
Avoidance: Embrace an iterative design process involving cycles of testing, output analysis, and prompt refinement.
Pitfall: Designing an extensive Mega-Prompt without considering token limits until the final stages.
Avoidance: Maintain an awareness of token economy throughout the design process, making strategic decisions about information density and conciseness.
General Pitfalls (Applicable to Both):
Pitfall: Lack of clarity and specificity in instructions or examples.
Avoidance: Be explicit in all instructions, define any potentially ambiguous terms, and provide sufficient context.
Pitfall: Failing to tailor the prompt (whether MOF-enhanced or a Mega-Prompt) to the specific strengths, weaknesses, or known behaviors of the target LLM model. Different models may respond differently to the same prompt structure.
Avoidance: If feasible, experiment with prompts across different models or model versions. Always re-test prompts when migrating to a new model or a new version of an existing model, as behavior can change.
The limitations and challenges associated with MOF and Mega-Prompts underscore a broader principle in prompt engineering: there is no universally optimal prompting technique that works best in all situations—a concept reminiscent of the "No Free Lunch" theorem in optimization. Each advanced technique comes with its own set of trade-offs. MOF, for example, offers increased robustness to stylistic variance, but at the cost of the effort required to create diverse example styles. Mega-Prompts provide enhanced control and precision for complex tasks, but this is achieved at the expense of increased design time, longer processing costs, and potentially reduced LLM creativity. Therefore, the choice and application of prompting techniques must be context-dependent, carefully tailored to the specific goals of the task, the characteristics of the LLM being used, and the practical constraints of the application.
The considerable manual effort involved in meticulously designing diverse stylistic examples for MOF, or in crafting, debugging, and refining lengthy Mega-Prompts , represents a significant bottleneck in scaling these advanced techniques. These challenges highlight the growing importance and value of research into "meta-prompting" strategies or Automated Prompt Optimization (APO) methods. Techniques such as Automatic Prompt Engineer (APE) , or approaches that can automatically generate and select effective few-shot examples , aim to alleviate this manual burden. The inherent difficulties and time investment associated with manual prompt design serve as a strong motivator for further advancements in APO, which could make sophisticated prompting more accessible and efficient.
Furthermore, the "brittleness" that MOF is designed to address—the sensitivity of LLMs to superficial, non-semantic changes in prompt format —may, in part, be a symptomatic characteristic of current LLM architectures or their training methodologies. While MOF provides a valuable solution for mitigating this issue with contemporary models , it is conceivable that future generations of LLMs could be designed or trained in ways that inherently promote better separation of form and content. Such advancements might lead to models that are intrinsically less susceptible to this specific type of stylistic brittleness. If this were to occur, the critical need for MOF as it is currently conceived might diminish, although the underlying principles of exposing models to diverse data representations during learning or inference could still hold relevance in other forms.
Ethical Prompting: A Proactive Stance on AI Fairness and Safety
The Path Forward: Future Directions in Advanced Prompt Engineering
The field of advanced prompt engineering is dynamic and rapidly evolving, with ongoing research and practical application continuously shaping its trajectory. Several emerging trends and potential evolutionary paths for techniques like MOF and Mega-Prompts, alongside the growing strategic importance of sophisticated prompting, indicate a vibrant future for this critical aspect of LLM interaction.
Emerging Trends and Potential Evolution of MOF, Mega-Prompts, and Related Techniques
The development of advanced prompting is moving towards greater sophistication, automation, and integration:
Automation in Prompt Design: A significant trend is the increasing use of AI-assisted methods for prompt generation, optimization, and refinement. Techniques like Automatic Prompt Engineer (APE) and automatic generation of Chain-of-Thought (Auto-CoT) examples aim to reduce the manual effort involved in crafting effective prompts. The future likely holds more tools that automate aspects of prompt discovery and tuning.
Dynamic and Adaptive Prompts: Prompts are evolving from static sets of instructions to more dynamic and adaptive frameworks. This includes "meta-prompting," where an LLM might first be tasked with generating a well-structured prompt based on a user's high-level goal, which is then used to elicit the final desired response. Prompts may also adapt based on the ongoing context of an interaction or intermediate outputs from the LLM.
Hierarchical and Modular Prompt Structures: There is a move towards designing complex prompts using reusable components, modules, or templates. This allows for more systematic construction of sophisticated prompts and facilitates easier maintenance and updating. For instance, a "Content Stratification" approach might break down a large prompting task into logical modules, each with its own template.
Integration with External Tools and Knowledge Bases: Prompting techniques are becoming more sophisticated in their ability to instruct LLMs to interact with external tools, APIs, or real-time knowledge sources. Frameworks like ReAct (Reasoning and Acting) and approaches for Conversational Retrieval Augmented Generation (RAG) exemplify this trend, enabling LLMs to perform actions and access up-to-date information beyond their training data.
Personalized Prompting: Future systems may increasingly tailor prompts based on individual user profiles, preferences, or past interaction histories, leading to more personalized and effective LLM assistance.
Evolution of MOF: The principles of MOF could be integrated into automated prompt optimization systems that automatically generate or select stylistically diverse examples. It might also be combined more formally with techniques that optimize the semantic content or relevance of few-shot examples.
Evolution of Mega-Prompts: Mega-Prompts could become more dynamic, with different sections or modules being activated, deactivated, or modified based on the evolving state of a complex task. There may also be a development of standardized schemas, domain-specific languages (DSLs), or graphical interfaces for constructing and managing these extensive prompt architectures.
The Growing Importance of Sophisticated Prompting Strategies
As LLMs continue to increase in power, capability, and integration into diverse real-world applications, the ability to guide and control them effectively through sophisticated prompting strategies will become even more critical. Prompt engineering is rapidly transitioning from a niche technical skill to a fundamental component of AI development, application, and effective use. For many users and developers, it is becoming a universal skill, analogous to proficiency in using spreadsheets or search engines, but essential for interacting with the next generation of AI tools.
The continuous expansion of LLM context windows will further broaden the horizons for techniques like Mega-Prompts, allowing for even more detailed instructions, a greater number of examples in many-shot learning scenarios, and the inclusion of more extensive contextual information directly within the prompt.
Ethical Prompting and Safety Considerations
Alongside advancements in efficacy and sophistication, there is a growing and crucial focus on the ethical dimensions of prompt engineering. This includes the development of techniques and best practices for designing prompts that actively reduce bias in LLM outputs, prevent the generation of harmful or inappropriate content, and ensure fairness and safety in AI applications. Designing prompts with ethical considerations in mind will be an integral part of advanced prompt engineering.
Furthermore, as LLMs become more powerful, the need for robust defenses against adversarial prompts and prompt injection attacks—where malicious instructions are hidden within seemingly benign inputs to trick the LLM into unintended actions or revealing sensitive information—will intensify. Research into secure prompting techniques is a vital parallel track in the evolution of the field.
The trajectory of advanced prompting frameworks suggests a potential "democratization" of fine-grained LLM control. As sophisticated techniques like MOF and Mega-Prompts become better understood, more widely adopted, and potentially abstracted into user-friendly tools, platforms, or standardized frameworks (e.g., no-code AI platforms ), they could empower a broader range of users. Individuals without deep machine learning expertise might leverage these advanced interaction paradigms to build complex and tailored AI applications, thereby shifting some degree of control and creative power from those who can fine-tune model weights to those who can master these intricate prompting methodologies.
In an environment where access to powerful base LLMs (such as the GPT series, Claude, and Gemini models) is increasingly commoditized through APIs, the unique value proposition of an AI application will progressively depend not just on the underlying model but also on the proprietary, sophisticated prompt engineering layered on top. Well-crafted Mega-Prompts, MOF-enhanced few-shot example sets, or novel combinations of advanced prompting techniques could become valuable intellectual property and a key competitive differentiator for businesses and developers seeking to create unique and superior AI-driven solutions.
Finally, the development of LLMs and the evolution of prompting techniques are deeply intertwined in a co-evolutionary process. New capabilities in LLMs, such as larger context windows or enhanced reasoning abilities, enable and inspire new and more powerful prompting methods (e.g., more extensive Mega-Prompts, more effective many-shot learning). Conversely, the challenges encountered and successes achieved in the field of prompt engineering—such as the identification of prompt brittleness which spurred the development of MOF —provide crucial feedback that can inform the design, training objectives, and architectural refinements of future LLMs. This symbiotic relationship, where advancements in one area fuel innovation in the other, will continue to drive progress in both LLM technology and the art and science of interacting with them.
Conclusion
The exploration of Mixture of Formats (MOF) and Mega-Prompts reveals two potent, yet distinct, advanced strategies for enhancing interactions with Large Language Models. MOF primarily addresses the challenge of prompt brittleness by desensitizing LLMs to superficial stylistic variations in few-shot examples, thereby fostering more robust and consistent performance. Its methodology, inspired by diversity in computer vision datasets, encourages models to focus on semantic content over presentation style, leading to measurable improvements in performance stability and, often, accuracy.
Mega-Prompts, on the other hand, tackle the need for precise guidance in complex tasks by enabling the construction of comprehensive, multi-faceted instructions. By meticulously defining actions, steps, personas, context, constraints, and output formats, Mega-Prompts empower users to exert a high degree of control over LLM behavior, facilitating the generation of detailed, accurate, and highly specific outputs. The development of Mega-Prompts is an iterative process, demanding careful design and refinement, but offering unparalleled command over sophisticated LLM applications.
While MOF focuses on how LLMs learn from examples, Mega-Prompts dictate what the LLM should do overall and how it should do it. There is clear potential for synergy, particularly by applying MOF principles to the examples embedded within a Mega-Prompt, thereby enhancing the robustness of the learning component within a larger instructional framework. However, both techniques come with their own trade-offs in terms of development effort, computational cost, and specific applicability, underscoring that no single prompting method is universally optimal.
The effective implementation of these advanced techniques is significantly bolstered by best practices such as the use of structured formatting (Markdown, JSON), strategic integration with other prompting methods like Chain-of-Thought and role prompting, systematic debugging, and diligent token optimization. These practices are not merely auxiliary but are integral to harnessing the full potential of MOF and Mega-Prompts.
The limitations inherent in these techniques—such as the effort required for MOF style creation or the complexity and token demands of Mega-Prompts—highlight the ongoing evolution of the field. They point towards a future where automated prompt optimization, dynamic and adaptive prompting frameworks, and modular prompt design will likely play increasingly significant roles.
Ultimately, MOF and Mega-Prompts exemplify the broader trend in prompt engineering towards more sophisticated, structured, and strategically designed interactions with LLMs. As these models become more deeply integrated into various facets of research, industry, and daily life, the ability to communicate with them effectively and reliably through advanced prompting will transition from a specialized skill to a fundamental competency. The continued co-evolution of LLM capabilities and prompting methodologies promises a future where human-AI collaboration can achieve unprecedented levels of precision, complexity, and utility. The journey into advanced prompt engineering is not just about eliciting better answers; it is about architecting more intelligent and dependable interactions with the powerful language technologies that are reshaping our world.
Frequently Asked Questions (FAQ)
What is the main goal of Mixture of Formats (MOF) in prompt engineering? MOF aims to make Large Language Models (LLMs) more robust and less sensitive to small, non-semantic changes in the formatting of few-shot examples within a prompt. This is often referred to as reducing "prompt brittleness".
How does MOF work? MOF works by presenting each few-shot example (input-output demonstration) within a single prompt using a different stylistic format. This diversification discourages the LLM from overfitting to a specific presentation style and encourages it to focus on the underlying task. Some MOF implementations also instruct the LLM to rephrase examples in yet another style.
What are "Mega-Prompts"? Mega-Prompts are highly detailed and comprehensive instructions given to an LLM to guide its responses and actions with precision, especially for complex tasks. They are often much longer than standard prompts, sometimes spanning one to two pages, and aim to minimize ambiguity by providing extensive directives upfront.
What are the key components of an effective Mega-Prompt? Effective Mega-Prompts typically include several components, often remembered by the acronym ASPECCTs: Action (the main task), Steps (detailed breakdown), Persona (role for the LLM), Examples (illustrations of desired output), Context (background information), Constraints (rules or limitations), and Template (desired output format). Tone is also an important consideration.
Can MOF and Mega-Prompts be used together? Yes, they can be used synergistically. The "Examples" component of a Mega-Prompt can benefit from MOF by presenting those illustrative examples in varied formats. This can enhance the robustness of the Mega-Prompt by making the LLM less sensitive to stylistic inconsistencies in the examples it learns from.
What are the main benefits of using MOF? MOF can lead to increased consistency in LLM performance despite stylistic variations in examples and may improve the LLM's ability to generalize from those examples. It has been shown to reduce the performance difference between the best and worst-performing prompt formats and can improve both minimum and maximum accuracy.
What are the main benefits of using Mega-Prompts? Mega-Prompts offer a high degree of control over the LLM's output, leading to greater accuracy for complex tasks. They allow for detailed specification of output structures, styles, and adherence to specific requirements.
What are some limitations of MOF? MOF is not a universal solution and may not improve performance in all tasks or with all LLMs; empirical testing is necessary. Creating diverse yet semantically equivalent stylistic variations for examples can require significant effort. MOF addresses stylistic sensitivity but doesn't fix issues with fundamentally flawed or irrelevant examples.
What are some limitations of Mega-Prompts? Crafting effective Mega-Prompts involves a learning curve and considerable design and iteration effort. They can lead to longer processing times and higher costs due to their length. There's also a risk of over-constraining the LLM, potentially stifling creativity, or confusing the LLM if the prompt is poorly structured. Token limits of LLMs also constrain the length and detail of Mega-Prompts.
How does structured formatting like Markdown help in prompt engineering? Structured formatting, such as Markdown, enhances the clarity and readability of prompts for both humans and LLMs. It allows for clear sectioning, hierarchical instructions, and lists, making complex prompts easier to parse and understand, which can lead to better LLM outputs. LLMs often process Markdown efficiently due to its simple syntax.
What is "prompt brittleness" that MOF tries to address? Prompt brittleness refers to the phenomenon where LLMs show significant performance changes in response to minor, non-semantic alterations in the prompt's format, such as extra spaces, different punctuation, or reordering of examples.
How are Mega-Prompts different from typical chatbot interactions? Mega-Prompts aim to provide all necessary detailed instructions upfront in a single, comprehensive input. This contrasts with typical chatbot interactions where users often clarify their intent and refine the task over several conversational turns.
What is the role of "token limits" in using Mega-Prompts? LLMs have maximum token limits for the input they can process (prompt + output). Since Mega-Prompts are long and detailed, they consume more tokens, which can lead to higher costs and potentially hit these limits, requiring careful optimization to balance detail with efficiency.
What are some common pitfalls when creating Mega-Prompts? Common pitfalls include creating information overload without clear structure, leading to LLM confusion ; including conflicting instructions ; neglecting the iterative development process ; and not considering token limits during design.
What is the future direction for advanced prompt engineering techniques like MOF and Mega-Prompts? Future trends include greater automation in prompt design, development of dynamic and adaptive prompts, more modular and hierarchical prompt structures, and deeper integration with external tools and knowledge bases. Ethical considerations and safety in prompting are also becoming increasingly important.
Additional Resources
For readers interested in exploring these topics further, the following external resources provide valuable insights and research:
Towards LLMs Robustness to Changes in Prompt Format Styles - The original research paper on ArXiv that introduces and evaluates the Mixture of Formats (MOF) technique.
Prompt Engineering Guide - A comprehensive and regularly updated guide covering a wide range of prompting techniques, from basic to advanced.
Azure OpenAI's Guide to Prompt Engineering Techniques - Microsoft's official documentation offering practical advice and patterns for effective prompting with large-scale models.
Bias and Fairness in AI: A Technical Perspective - An in-depth article that breaks down the technical aspects of AI bias and the strategies being used to create more equitable systems.