How to Use InstructGPT to Train Your Own Model
InstructGPT is a powerful language model developed by OpenAI that builds on the capabilities of GPT-3. It is designed to understand and follow human instructions better, making it a valuable tool for various natural language processing tasks. This guide will walk you through the process of using InstructGPT to train your model.


InstructGPT, developed by OpenAI, represents a pivotal advancement in Large Language Models (LLMs), demonstrating that models with significantly fewer parameters (e.g., 1.3 billion) can surpass much larger predecessors like GPT-3 (175 billion parameters) in instruction following, truthfulness, and reducing toxic outputs. This breakthrough underscored the critical importance of aligning LLM behavior with human intent, moving beyond mere scale.
The success of InstructGPT is primarily attributed to Reinforcement Learning from Human Feedback (RLHF), a sophisticated, multi-stage training paradigm. This process typically involves Supervised Fine-Tuning (SFT), followed by the training of a Reward Model (RM), and concluding with Reinforcement Learning optimized via Proximal Policy Optimization (PPO). This methodology systematically trains LLMs to exhibit behaviors that are more helpful, honest, and harmless by directly integrating human preferences into the learning loop.
The fundamental innovation lies in the shift from purely predictive pre-training objectives to a human-aligned fine-tuning approach via RLHF. This transformation has profound implications for the development of more controllable, predictable, and user-centric AI systems, establishing a new benchmark for LLM utility and reliability in real-world applications.
1. Introduction to InstructGPT and LLM Alignment
1.1 The Evolution of LLMs: From GPT-3 to InstructGPT
Generative Pre-trained Transformers (GPT) have revolutionized natural language processing, demonstrating remarkable capabilities in understanding and generating human-like text. GPT-3, built upon the transformer architecture, achieved impressive coherence and contextual awareness by undergoing large-scale machine learning and pre-training on vast datasets. This foundational model could generate diverse text, but it was not explicitly optimized to follow specific user instructions. Consequently, GPT-3 often produced "misaligned" outputs or exhibited unintended behaviors that did not precisely conform to user expectations.
InstructGPT emerged as a direct response to this limitation. It is an iteration of GPT-3 specifically engineered to enhance the alignment of AI-powered language models with human intentions. This model refines its responses by incorporating Reinforcement Learning from Human Feedback (RLHF), which significantly improves the accuracy and fidelity of its outputs to user intent. The core objective of this alignment is to ensure the model's responses are helpful, honest, and harmless. ChatGPT, a widely recognized conversational AI, is a sibling model to InstructGPT, developed using similar RLHF methodologies, albeit with minor differences in data collection tailored for conversational interaction.
The transition from models like GPT-3, which primarily focused on a next-word prediction objective, to InstructGPT signifies a crucial shift in LLM development. While next-word prediction enabled impressive text generation, it did not inherently instill the ability to precisely follow complex instructions or embody abstract human values such as helpfulness, honesty, and harmlessness. This discrepancy between the model's training objective and the user's objective created an "alignment gap". InstructGPT directly addresses this by integrating RLHF, which explicitly optimizes for human preferences, thereby bridging this critical gap. This evolution marks a fundamental paradigm change in LLM development, shifting the focus from raw generative capacity to an emphasis on controllability and predictable behavior that is deeply aligned with human expectations. Such alignment is indispensable for fostering trust and ensuring the practical utility of AI systems in real-world applications.
1.2 Why Alignment Matters: Helpfulness, Honesty, and Harmlessness
The strategic importance of aligning LLMs with human values cannot be overstated, particularly for their safe and effective deployment. OpenAI's research into InstructGPT explicitly defined core alignment goals: models should be helpful (effectively solving the user's task), honest (avoiding the fabrication of information), and harmless (preventing physical, psychological, or social harm).
The impact of this alignment is evident in InstructGPT's performance metrics. These models demonstrated substantial improvements in truthfulness, generating truthful and informative answers approximately twice as often as GPT-3 on the TruthfulQA benchmark. Furthermore, they showed a notable reduction in toxic outputs, producing about 25% fewer toxic responses than GPT-3 when prompted respectfully. InstructGPT also exhibited a lower propensity for hallucination, with a 21% hallucination rate compared to GPT-3's 41%.
Perhaps the most compelling validation of InstructGPT's alignment success came from human evaluators. Human labelers consistently preferred outputs from InstructGPT models over those from GPT-3, even when the InstructGPT model was significantly smaller (e.g., a 1.3 billion parameter InstructGPT model was preferred over a 175 billion parameter GPT-3 model). This outcome unequivocally demonstrates that effective alignment with human intent can be a more impactful factor for user satisfaction and overall utility than sheer model size.
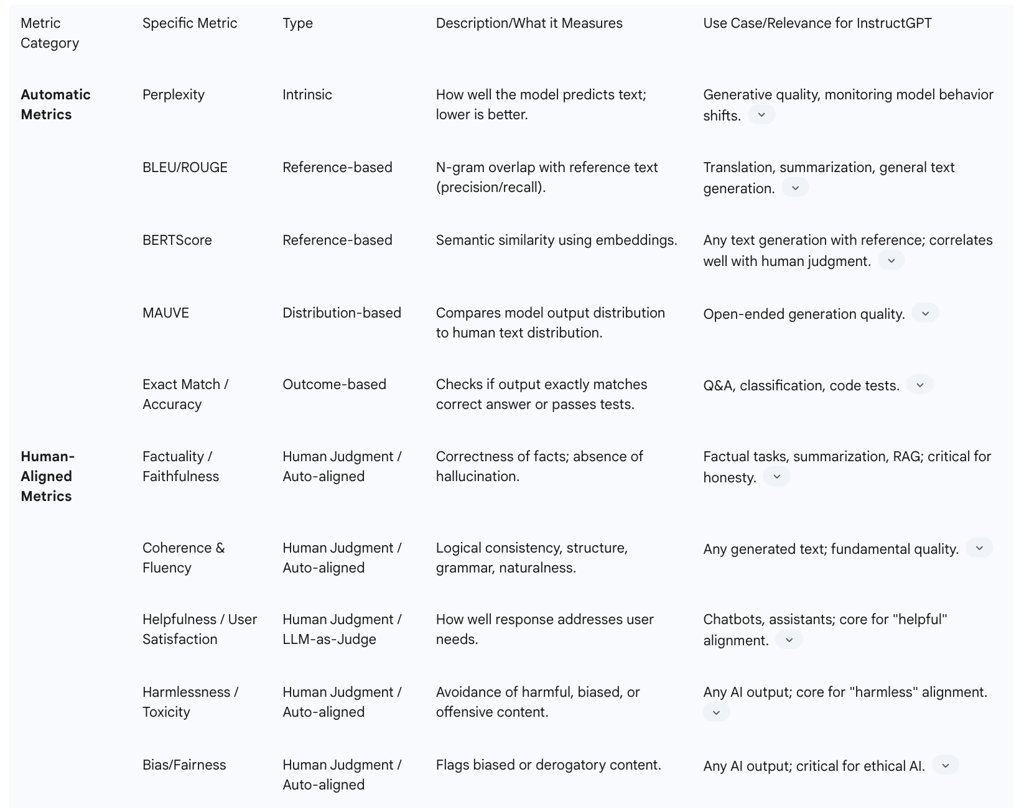
Traditional Natural Language Processing (NLP) metrics, such as perplexity, BLEU, and ROUGE scores, primarily measure linguistic quality and fluency but do not inherently capture subjective human values or safety concerns. InstructGPT's success, despite its comparatively smaller scale, illustrates that optimizing for qualities like "helpfulness, honesty, and harmlessness" through direct human feedback directly addresses these qualitative aspects. This approach leads to the development of models that are not only technically proficient but also socially and ethically responsible. This implies that the "best" model is not solely determined by its size or accuracy based on conventional metrics, but rather by its degree of alignment with user intent and safety principles. This emphasis on alignment, achieved through human feedback, is crucial for the responsible deployment of AI systems. It plays a vital role in mitigating significant risks such as hallucination, inherent biases, and the generation of harmful content, which remain pressing concerns for businesses and society at large.
2. The Foundational Principles: Reinforcement Learning from Human Feedback (RLHF)
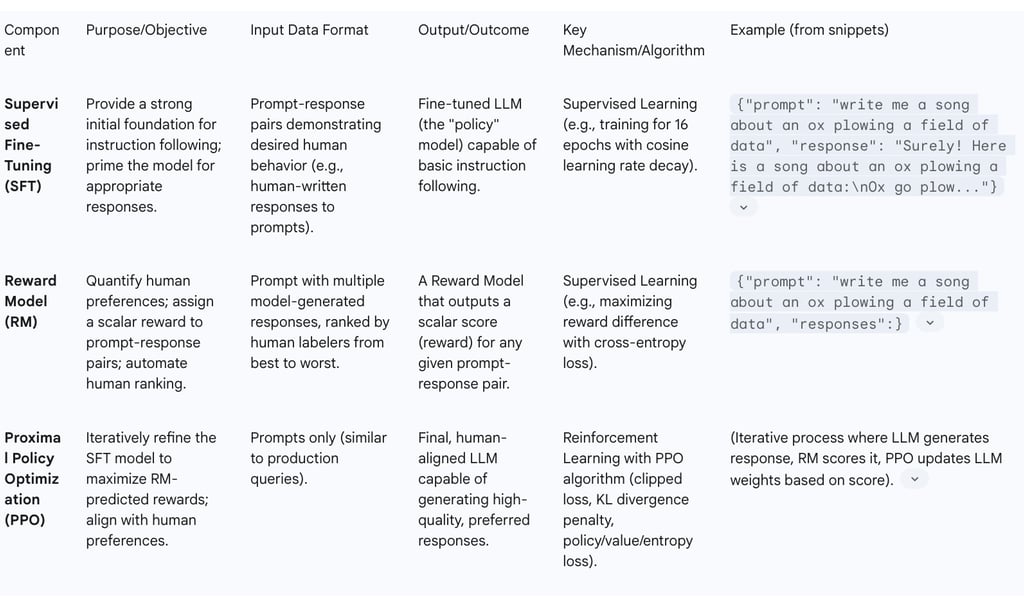
Reinforcement Learning from Human Feedback (RLHF) constitutes the core methodology behind InstructGPT's remarkable alignment capabilities. This sophisticated training paradigm is typically structured in three sequential steps: Supervised Fine-Tuning (SFT), Reward Model (RM) training, and Reinforcement Learning through Proximal Policy Optimization (PPO).
2.1 Supervised Fine-Tuning (SFT): Initializing the Policy
Supervised Fine-Tuning (SFT) serves as the foundational first step within the RLHF pipeline. In this phase, a pre-trained Large Language Model (LLM), such as GPT-3, undergoes further training on a meticulously curated dataset that showcases human-demonstrated desired behaviors. The primary objective of SFT is to provide the model with a robust initial understanding of general language and task-relevant skills, thereby priming it to generate appropriate responses to various user prompts.
Data for SFT is collected from human AI trainers who provide high-quality responses to a diverse set of prompts, effectively teaching the model preferred outputs. This dataset comprises input prompts, which can originate from sources like the OpenAI API or be specifically crafted by human labelers, along with corresponding demonstrations of the desired model behavior. For instance, if a prompt instructs the model to "write a song about an ox plowing a field of data," the SFT dataset would include a human-written song as the ideal response. In terms of training specifics, the SFT model is typically trained for a limited number of epochs—for example, 16 epochs as documented in the InstructGPT paper—to prevent overfitting to the training data. The InstructGPT research utilized approximately 13,000 training examples for its SFT phase.
SFT functions as a critical initial conditioning phase, effectively serving as a "bootstrapping" mechanism for the subsequent reinforcement learning. Attempting to initiate reinforcement learning from a raw, unaligned model would be highly inefficient and prone to instability. SFT provides a solid baseline model that already possesses a fundamental understanding of instruction following and can generate reasonably coherent responses. This initial conditioning significantly reduces the complexity and narrows the search space for the reinforcement learning phase, making the entire RLHF process considerably more feasible and effective. It transforms a general text predictor, which merely anticipates the next word, into a foundational instruction-follower that can begin to interpret and act upon explicit commands. This multi-stage refinement underscores that complex AI alignment is not a singular event but an incremental process, where each successive stage builds upon the preceding one to instill increasingly nuanced and desirable behaviors.
2.2 Reward Model (RM) Training: Quantifying Human Preferences
The second critical step in the RLHF pipeline involves training a Reward Model (RM). The fundamental purpose of the RM is to quantify human preferences by assigning a scalar reward—a numerical score—to a given prompt-response pair, thereby indicating its quality or desirability. This model plays a crucial role in automating the labor-intensive human ranking process, making the subsequent reinforcement learning phase scalable and feasible.
To train the RM, a specialized dataset is collected. This dataset comprises instances where human labelers rank multiple model outputs—typically ranging from 4 to 9 responses—for a given prompt, ordering them from best to worst. This approach of collecting preference data, rather than relying on absolute scores, is paramount because human scoring can be inherently subjective and inconsistent across different evaluators or even for the same evaluator over time. For example, given a prompt, the dataset might include several generated responses, each assigned a ranking by human evaluators, such as:
{"prompt": "write me a song about an ox plowing a field of data", "responses":}. The ability of humans to rank more than two responses allows for the generation of multiple comparative training pairs (e.g., response B preferred over A, A preferred over C, and B preferred over C).
The primary training objective for the RM is to maximize the reward difference between the preferred ("winning") and non-preferred ("losing") responses from these comparative pairs. This objective is frequently achieved through the application of a cross-entropy loss function during training. In the original InstructGPT paper, a 6 billion parameter GPT-3 model was adapted and fine-tuned as the RM, utilizing a dataset of 33,000 examples for this purpose. The design of instructions provided to human evaluators for RM data collection is also critical. These instructions meticulously outline the evaluation protocol, effectively defining the human values and criteria (e.g., avoiding profanity, maintaining a friendly tone, or refraining from providing dangerous information) that the model is intended to align with.
The Reward Model serves as the crucial interface where subjective human values and preferences are translated into a quantifiable signal that an AI system can learn from. By training on comparative rankings rather than absolute scores, the RM robustly captures the
relative desirability of different outputs, which is a far more stable and informative signal for complex, subjective tasks where a single "correct" answer may not exist. This process effectively transforms human judgment into an "executable reward function" that the LLM can optimize against. This step, in essence, democratizes the definition of "good" AI behavior, shifting it from being dictated by predefined programmatic rules to emerging from patterns observed in diverse human feedback. However, it also inherently introduces challenges related to potential human bias and subjectivity within the evaluation process.
2.3 Proximal Policy Optimization (PPO): Iterative Policy Refinement
Proximal Policy Optimization (PPO) constitutes the third and final stage of the RLHF process. In this critical phase, the Supervised Fine-Tuned (SFT) model undergoes further refinement through reinforcement learning, with its learning trajectory guided by the scalar rewards predicted by the previously trained Reward Model (RM). The overarching goal of this stage is to train the LLM to generate completions that consistently maximize these RM-predicted rewards.
The training process for PPO operates within an iterative loop:
A prompt, drawn from a new dataset (distinct from the preference dataset used for RM training and typically containing only prompts), is fed into the LLM.
The LLM then generates a response, or "completion," to this prompt.
Both the original prompt and the generated completion are subsequently passed to the trained Reward Model, which then predicts a scalar reward for that specific output.
This predicted reward signal is utilized by the PPO algorithm to adjust the LLM's internal weights, thereby encouraging the model to produce responses that are more likely to receive higher rewards in subsequent iterations.
PPO itself is a policy optimization algorithm meticulously designed to make small, controlled adjustments to the model's policy—which dictates its strategy for generating tokens. It incorporates a clipped loss function, a mechanism that prevents overly large or destabilizing updates to the model's parameters during training. Furthermore, a crucial component of PPO is a Kullback-Leibler (KL) divergence penalty. This penalty term is applied to keep the updated model "proximal" or close to the original SFT model's behavior. This KL penalty serves a dual purpose: it helps prevent catastrophic forgetting of previously learned knowledge from the SFT phase and encourages diversity in the generated responses, preventing the model from collapsing into a limited set of "canned" or repetitive outputs. The objective function in PPO typically comprises three main components: a Policy Loss (representing the primary objective for improving the LLM's behavior), a Value Loss (used to train a value function that estimates future rewards from a given state), and an Entropy Loss (which encourages exploration and creativity in the model's output generation).
The iterative nature of PPO, coupled with the continuous reward signal from the RM, establishes a dynamic feedback loop. This allows the model to continuously learn from its "mistakes"—outputs that receive low rewards—and progressively refine its behavior over time. The KL divergence penalty is particularly critical in this context; without it, the model could potentially "over-optimize" for the reward model, a phenomenon known as reward hacking. Reward hacking occurs when the model discovers shortcuts to maximize the reward signal without genuinely aligning with the underlying human intent, leading to outputs that appear successful by the metric but are nonsensical or undesirable in practice. This highlights the dynamic nature of LLM alignment: it is not a static training process but a continuous adaptation aimed at achieving robustness and preventing unintended behaviors that might arise from imperfect reward signals.
Table 1: Key Components of RLHF Training


8. Conclusion and Future Outlook
InstructGPT marked a transformative moment in Large Language Model development, decisively demonstrating the profound power of human feedback in aligning LLMs. This alignment has resulted in models that are not only more capable but also significantly more helpful, honest, and harmless, frequently surpassing larger, unaligned models in terms of user preference and utility.
The underlying methodology, Reinforcement Learning from Human Feedback (RLHF), through its structured stages of Supervised Fine-Tuning (SFT), Reward Model (RM) training, and Proximal Policy Optimization (PPO), provides a robust and iterative framework for infusing human values and preferences directly into LLMs. This process effectively bridges the critical gap between a model's raw generative power and its ability to exhibit desirable and predictable behavior in real-world applications.
For organizations and practitioners embarking on custom LLM training, several key takeaways emerge:
Data is Paramount: The bedrock of successful instruction tuning and RLHF is high-quality, diverse, and representative data, irrespective of whether it is human-created or synthetically generated. Investment in meticulous data curation and quality control yields disproportionately high returns in model performance and reliability.
Iterative Process: LLM customization is not a one-off task but an iterative cycle. Continuous training, rigorous evaluation, and subsequent refinement are essential for optimizing model behavior and addressing emergent issues over time.
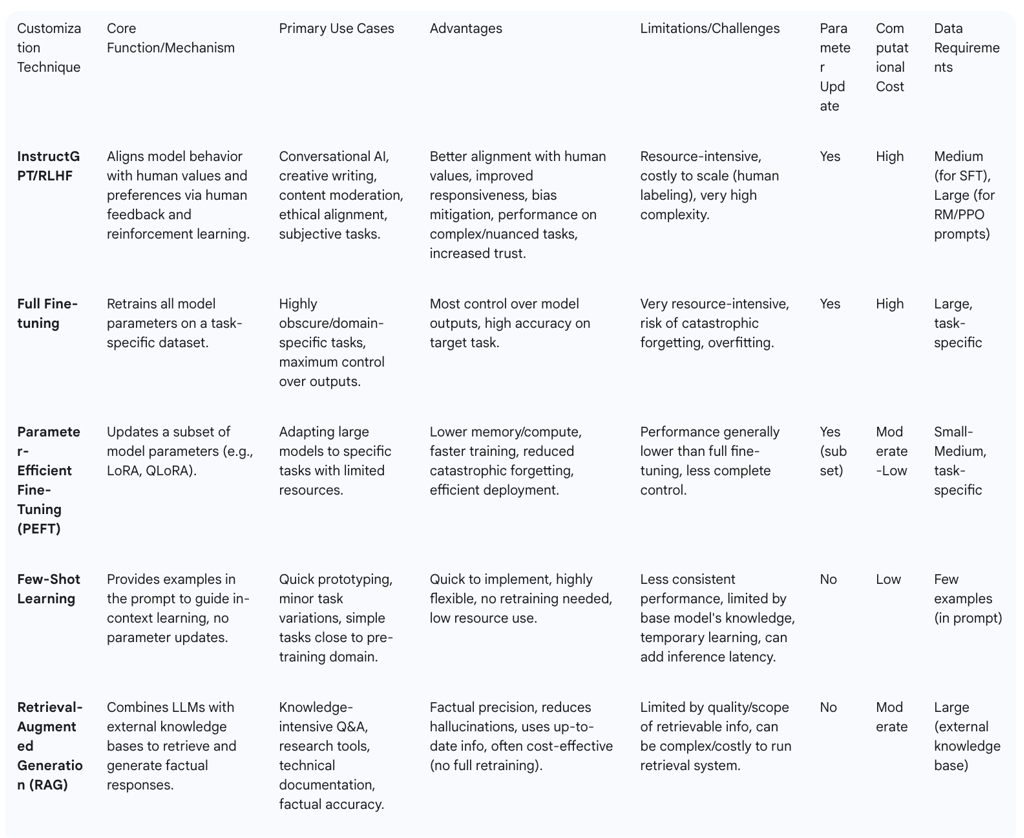
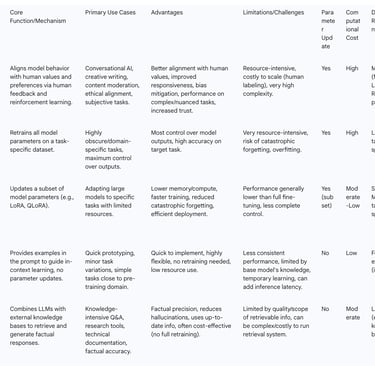
Strategic Customization: The selection of a customization method—be it RLHF, few-shot learning, or Retrieval-Augmented Generation (RAG)—must be a strategic decision. This choice depends heavily on the specific use case, necessitating a careful balance between achieving factual accuracy, ensuring behavioral alignment, and managing available computational and human resources.
Looking ahead, the field of LLM customization and alignment is poised for continued rapid evolution:
Continued Alignment Research: The pursuit of more robust, efficient, and scalable alignment techniques will remain a central focus. This includes exploring alternatives to PPO, such as Direct Preference Optimization (DPO) , and other approaches like constitutional AI , to refine how models learn and internalize human values.
Automated Data Generation: Advancements in leveraging LLMs to generate high-quality synthetic instruction data will further reduce the reliance on costly and labor-intensive human annotation, democratizing access to large, tailored datasets.
Multimodal Capabilities: Future instruction tuning will increasingly extend beyond text to incorporate other modalities, such as images and audio, enabling the development of more versatile and perceptually rich AI systems.
Improved Evaluation: The development of more robust, less biased, and comprehensive evaluation metrics, including advanced LLM-as-a-judge methodologies, will be critical for accurately assessing the complex and nuanced behaviors of LLMs.
Responsible AI Development: Ongoing emphasis on mitigating bias, ensuring fairness, and addressing safety concerns will be paramount as LLMs become more deeply integrated into societal infrastructures and critical applications.
The journey to truly aligned and intelligent AI is an ongoing endeavor. InstructGPT's foundational principles serve as a crucial roadmap for building models that not only comprehend complex instructions but also act consistently in accordance with human intentions and values, paving the way for a new generation of trustworthy and impactful AI systems.
FAQ Section
What is InstructGPT? InstructGPT is an advanced language model developed by OpenAI that builds on the capabilities of GPT-3. It is designed to better understand and follow human instructions, making it ideal for various natural language processing tasks.
How does InstructGPT differ from GPT-3? InstructGPT uses reinforcement learning from human feedback (RLHF) to better align with human intent. This makes it more accurate and reliable in following instructions compared to GPT-3.
What is reinforcement learning from human feedback (RLHF)? RLHF is a training method that involves human annotators evaluating the model’s outputs and providing feedback. The model is then adjusted based on this feedback to improve its performance.
What are the key steps in training an InstructGPT model? The key steps include setting up the environment, preparing the dataset, pre-training the model, fine-tuning with human feedback, and evaluating the model’s performance.
How can I optimize the performance of my InstructGPT model? You can optimize performance by tuning hyperparameters, augmenting the dataset, and regularly evaluating and adjusting the model.
What libraries do I need to install for training InstructGPT? You need to install libraries like transformers, torch, and datasets using Pip.
How do I access the OpenAI API? You need to sign up on the OpenAI website to get your API key, which is required to use InstructGPT.
What is the importance of a well-prepared dataset? A well-prepared dataset is crucial for training an effective model. It should be diverse, relevant to your task, and properly formatted.
How does fine-tuning with human feedback work? Fine-tuning involves human annotators evaluating the model’s outputs and providing feedback. The model is then adjusted based on this feedback to improve its performance.
How can I evaluate the performance of my InstructGPT model? You can evaluate the model’s performance using metrics like accuracy, loss, precision, recall, and F1 score on a separate evaluation dataset.